
Log Contention -Redo and Undo
This, like the cannot allocate new log message, is something the DBA must fix, typically in conjunction with the system administrator. However, it is something a developer might detect as well if the DBA isn’t watching closely enough.
If you are faced with log contention, what you might observe is a large wait time on the “log file sync” event and long write times evidenced in the “log file parallel write” event in a Statspack report. If you see this, you may be experiencing contention on the redo logs; they are not being written fast enough.
This can happen for many reasons. One application reason (one the DBA can’t fix, but the developer must) is that you are committing too frequently—committing inside of a loop doing INSERTs, for example. As demonstrated earlier in the “What Does a COMMIT Do?” section, committing too frequently, aside from being a bad programming practice, is a surefire way to introduce lots of log file sync waits.
Assuming all of your transactions are correctly sized (you are not committing more frequently than your business rules dictate), the most common causes for log file waits that I’ve seen are as follows:
•\ Putting redo on a slow device: The disks are just performing poorly. It is time to buy faster disks.
•\ Putting redo on the same device as other files that are accessed frequently: Redo is designed to be written with sequential writes and to be on dedicated devices. If other components of your system— even other Oracle components—are attempting to read and write to this device at the same time as LGWR, you will experience some degree of contention. Here, you want to ensure LGWR has exclusive access to these devices if at all possible.
•\ Mounting the log devices in a buffered manner: Here, you are using a “cooked” file system (not RAW disks). The operating system is buffering the data, and the database is also buffering the data (redo log buffer). Double buffering slows things down. If possible, mount the devices in a “direct” fashion. How to do this varies by operating system and device, but it is usually possible.
•\ Putting redo on a slow technology, such as RAID-5: RAID-5 is great for reads, but it is generally terrible for writes. As we saw earlier regarding what happens during a COMMIT, we must wait for LGWR to ensure the data is on disk. Using any technology that slows this down is not a good idea.
If at all possible, you really want at least five dedicated devices for logging and optimally six to mirror your archives as well. In these days of 200GB, 300GB, 1TB, and larger disks, this is getting harder, but if you can set aside four of the smallest, fastest disks you can find and one or two big ones, you can affect LGWR and ARCn in a positive fashion. To lay out the disks, you would break them into three groups (see Figure 9-6):
•\ Redo log group 1: Disks 1 and 3
•\ Redo log group 2: Disks 2 and 4
•\ Archive: Disk 5 and optionally disk 6 (the big disks)
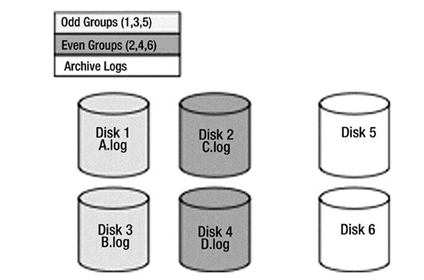
Figure 9-6. Optimal redo log configuration
You would place redo log group 1 with members A and B onto disks 1 and 3. You would place redo log group 2 with members C and D onto disks 2 and 4. If you have groups 3, 4, and so on, they’d go onto the odd and even groups of disks, respectively.
The effect of this is that LGWR, when the database is currently using group 1, will write to disks 1 and 3 simultaneously. When this group fills up, LGWR will move to disks 2 and 4.
When they fill up, LGWR will go back to disks 1 and 3. Meanwhile, ARCn will be processing the full online redo logs and writing them to disks 5 and 6, the big disks. The net effect is neither ARCn nor LGWR is ever reading a disk being written to, or writing to a disk being read from, so there is no contention (see Figure 9-7).
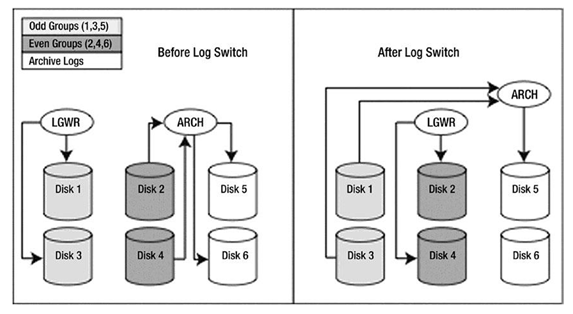
Figure 9-7. Redo log flow
So, when LGWR is writing group 1, ARCn is reading group 2 and writing to the archive disks. When LGWR is writing group 2, ARCn is reading group 1 and writing to the archive disks. In this fashion, LGWR and ARCn each have their own dedicated devices and will not be contending with anyone, not even each other.
Temporary Tables and Redo
Oracle comes with two types of temporary tables: global and private. Global temporary tables have been a feature within Oracle for a long time. Global temporary tables are permanent database objects that persist on disk and are visible to all sessions. They are named temporary tables because the data within them only persists for the duration of the transaction or session.
Starting with Oracle 18c, you can create a private temporary table. Unlike a global temporary table, a private temporary table exists only in memory and is only visible to the session that created it. You can define a private temporary table to persist per transaction or session duration, after which the temporary table is automatically dropped.
Note If you’ve worked with other database technologies such as SQL Server or MySQL, a private temporary table aligns more with what you’ve used in those environments.
Even though global temporary tables have been around for a while, there is still some confusion surrounding them, in particular in the area of logging. In this section, we’ll also explore the question “How do temporary tables work with respect to logging of changes?”